"현재의 네이티브 앱들의 기능과 유사한 형태의 웹 어플리케이션을 구현할 때 가장 난해한 부분은 어떤 것일까요? 아마 그래픽스, 성능, 네트워크 등 다양한 의견이 나오리라 생각됩니다만, 단언컨데 현재 가장 어려운 부분 중의 하나는 오프라인입니다. 서비스워커는 브라우저 측에서 동작하는 이벤트 기반의 시스템 Worker입니다. 이를 이용하여 오프라인 앱을 위한 리소스 관리, 원격 푸시 등을 직접 관리할 수 있습니다. 네이티브 어플리케이션에서는 일반화되어 있는 개념이기도 하지만 기존의 웹 개발에 익숙한 분들에게는 생소한 접근일 수 있습니다만 반드시 알아두어야 할 기능이라고 할 수 있겠습니다."

TL;DR;
초기부터 웹은 다양한 서버에 저장되어 있는 문서를 연결하기 위해 요청(Request) 및 응답(Response)의 메커니즘을 기반으로 동작하도록 설계되었습니다. 다시 말해 서버와 클라이언트가 네트워크를 통해 리소스를 송수신하도록 처리하고 있으며, 이 때문에 웹 페이지 자체의 성능 외에도 근본적으로 오프라인을 기반으로 하는 실행 환경은 아닌 것입니다.
서비스워커는 1차적으로는 이러한 오프라인의 문제를 해결하기 위한 시작점입니다. 물론 서비스워커가 해결하고자 하는 문제의 범위는 이보다 더 넓습니다. 오프라인은 시작일 뿐이지만 비유하자면 네이티브 어플리케이션의 동작 흐름을 웹으로 가져오기 위한 가장 중요한 기능이라고 할 수 있겠습니다.
이 튜토리얼에서는 서비스워커를 이용하여 브라우저의 캐시 시스템을 생성하고 관리하는 방법과 이를 통해 웹 페이지에서 사용하는 모든 리소스에 대한 오프라인 동작을 수행하는 방법을 알아봅니다.
> 서비스워커란
서비스워커는 웹페이지나 사용자 인터랙션이 필요하지 않은 기능들을 위한 기회를 제공하고, 웹페이지와는 별개로 여러분의 브라우저에 의해 백그라운드에서 실행되는 스크립트 기반의 워커(Worker)입니다.
이 기능은 앞으로 여러가지 연동 기능을 예정하고 있으며 네트워크 요청을 가로채고, 응답을 조작하기 위한 프로그래밍 가능한 캐시를 제어할 수 있는 기능을 현재 크롬에서 제공합니다.
> 서비스워커의 생명주기
서비스워커는 웹페이지와 완전하게 별개인 생명주기(Life Cycle)를 가지고 있으며, register를 통해 백그라운드에서 서비스워커의 설치 과정을 시작합니다.
설치 과정에서 리소스를 캐싱하고자 할 때 모든 파일이 성공적으로 캐싱되고 나면 서비스워커는 설치 상태가 되지만 만약 어떠한 파일이라도 다운로드나 캐싱에 실패한다면, 설치 과정 역시 실패하고 서비스워커는 활성화되지 않습니다.
설치가 이루어졌을 때 이어서 활성화 단계가 수행되며, 이는 우리가 서비스워커 갱신하기 섹션에서 다룰 기존 캐시의 관리를 위한 시점으로 활용할 수 있습니다.
활성화 단계 후에 서비스워커는 페이지가 등록한 서비스워커는 범주(scope) 내에 닿는 모든 페이지를 제어하게 되며 페이지로부터 네트워크 요청이나 메세지가 생성될 때 발생하는 fetch와 message를 제어하게 됩니다.
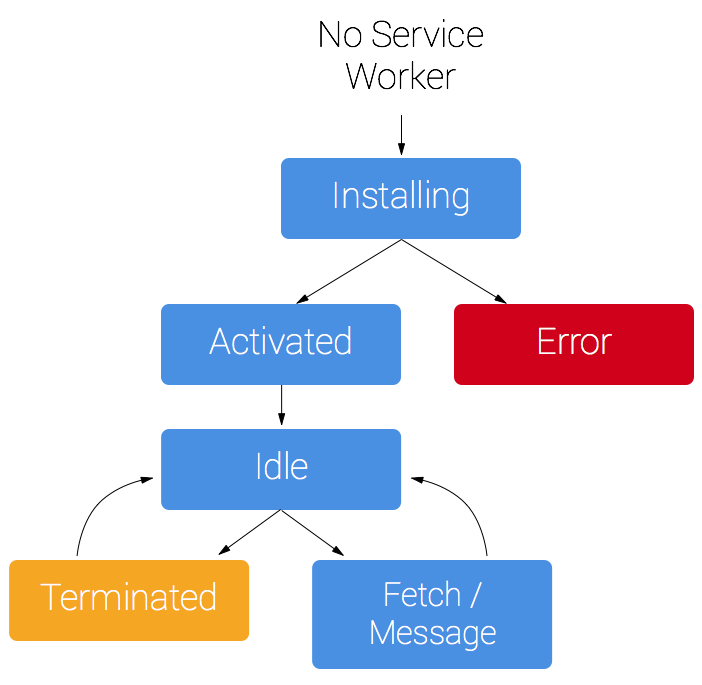 |
| 단순화한 서비스워커의 생명 주기 |
> 서비스워커를 사용하기 위한 몇 가지 사항
서비스워커는 지대한 영향을 줄 수 있는 서비스워커 모듈의 신뢰성을 위해 HTTPS 기반으로만 동작합니다. 또한, 현재 시점에서 캐시 시스템은 폴리필을 통해서만 사용할 수 있습니다.
자세한 내용은 튜토리얼을 참조하시기 바랍니다.
번역 링크
- 서비스워커 소개: 서비스워커는 어떻게 사용하는가






